HALOOP
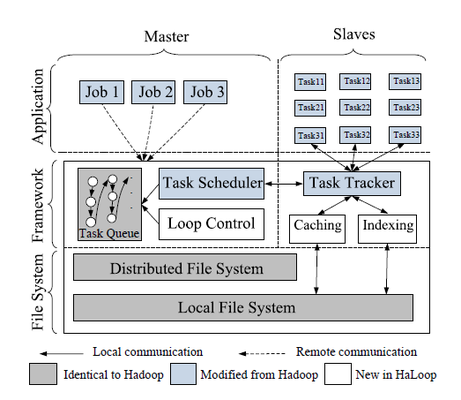
HaLoop was developed by YingYi Bu, Bill Howe, and Magda Balazinska auniversity of washington. HaLoop is nothing but an extension of Hadoop which along with processing of data provides and interesting way to perform iterative computation on the data.
Architecture
HaLoop is a great extension for Hadoop as it provides support for iterative application. In order to meet these requirement the changes that are made in Hadoop to efficiently support Iterative data analysis are:
1.) Providing a new application programming interface to simplify the iterative expressions.
2.) An automatic generation of Map reduce program by the master node using a loop control module until the loop condition is met.
3.) The new task scheduler supports data locality in these application in order to efficiently perform iterative operations.
4.) The task scheduler and task tracker are modified not only to manage execution but also manage cache indices on slave module.
Some of the important feature of HaLoop which makes all these feasible are:
1.) Inter-iteration Locality : The major goal of HaLoop is to keep the data for map and reduce that uses same data on different iteration on the same machine. Here data is easily cached and is reused for various other application.
2.) Reducer Input Cache: HaLoop will cache reducer inputs across all reducers and create a local index for the cached data. Additionally, the reducer inputs are cached before each reduce function invocation, so that tuples in the reducer input cache are sorted and grouped by reducer input key.
3.) Reducer Output Cache: The reducer output cache stores and indexes the most recent local output on each reducer node. This cache is used to reduce the cost of evaluating fixpoint termination conditions. That is, if the application must test the convergence condition by comparing the current iteration output with the previous iteration output, the reducer output cache enables the framework to perform the comparison in a distributed fashion.The reducer output
4.) Mapper Input Cache: HaLoop’s mapper input cache aims to avoid non-local data reads in mappers during non-initial iterations. In the first iteration, if a mapper performs a non-local read on an input split, the split will be cached in the local disk of the mapper’s physical node. Then, with loop-aware task scheduling, in later iterations, all mappers read data only from local disks, either from HDFS or from the local file system
Program on HaLoop :
In order to write a HaLoop program we need to follow following steps:
1.) Loop body (as one or more mapreduce pair)
2.) terminating condition and loop invariant data (optional)
3.) Map function to convert input key-value pair into intermediate (in_key,in_value) pair.
4.) reduce function to produce (out_key,out_value)
To make a termination decision we have introduced a Fixpoint operator to MapReduce. The Fixpoint operator signals when the distributed computation should end. Few function supported to figure out these fixed points are:
1.) SetFixedPointThreshold sets a distance between one iteration and the next.
2.) ResultDistance It is distance between two output from the iteration where the iteration should stop.
3.) SetMaxNumOfIterations: Additional addition to control the loop statement. HaLoop terminates job if number of iteration > SetMaxNumOfIterations.
4.) SetIterationInput: associates an input source for each iteration.
5.) AddStepInput: This associates an additional input source with an intermediate map-reduce pair in the loop body
6.) AddInvariantTable: specifies an input HDFS file which is loop invariant.
Architecture
HaLoop is a great extension for Hadoop as it provides support for iterative application. In order to meet these requirement the changes that are made in Hadoop to efficiently support Iterative data analysis are:
1.) Providing a new application programming interface to simplify the iterative expressions.
2.) An automatic generation of Map reduce program by the master node using a loop control module until the loop condition is met.
3.) The new task scheduler supports data locality in these application in order to efficiently perform iterative operations.
4.) The task scheduler and task tracker are modified not only to manage execution but also manage cache indices on slave module.
Some of the important feature of HaLoop which makes all these feasible are:
1.) Inter-iteration Locality : The major goal of HaLoop is to keep the data for map and reduce that uses same data on different iteration on the same machine. Here data is easily cached and is reused for various other application.
2.) Reducer Input Cache: HaLoop will cache reducer inputs across all reducers and create a local index for the cached data. Additionally, the reducer inputs are cached before each reduce function invocation, so that tuples in the reducer input cache are sorted and grouped by reducer input key.
3.) Reducer Output Cache: The reducer output cache stores and indexes the most recent local output on each reducer node. This cache is used to reduce the cost of evaluating fixpoint termination conditions. That is, if the application must test the convergence condition by comparing the current iteration output with the previous iteration output, the reducer output cache enables the framework to perform the comparison in a distributed fashion.The reducer output
4.) Mapper Input Cache: HaLoop’s mapper input cache aims to avoid non-local data reads in mappers during non-initial iterations. In the first iteration, if a mapper performs a non-local read on an input split, the split will be cached in the local disk of the mapper’s physical node. Then, with loop-aware task scheduling, in later iterations, all mappers read data only from local disks, either from HDFS or from the local file system
Program on HaLoop :
In order to write a HaLoop program we need to follow following steps:
1.) Loop body (as one or more mapreduce pair)
2.) terminating condition and loop invariant data (optional)
3.) Map function to convert input key-value pair into intermediate (in_key,in_value) pair.
4.) reduce function to produce (out_key,out_value)
To make a termination decision we have introduced a Fixpoint operator to MapReduce. The Fixpoint operator signals when the distributed computation should end. Few function supported to figure out these fixed points are:
1.) SetFixedPointThreshold sets a distance between one iteration and the next.
2.) ResultDistance It is distance between two output from the iteration where the iteration should stop.
3.) SetMaxNumOfIterations: Additional addition to control the loop statement. HaLoop terminates job if number of iteration > SetMaxNumOfIterations.
4.) SetIterationInput: associates an input source for each iteration.
5.) AddStepInput: This associates an additional input source with an intermediate map-reduce pair in the loop body
6.) AddInvariantTable: specifies an input HDFS file which is loop invariant.
Performance Evaluation
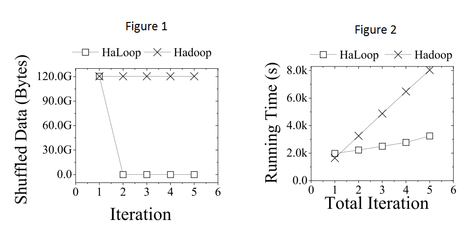
The figure on the left compares the performance of HaLoop for the iterative algorithms.
Figure 1 sows that HaLoop need not shuffle the constant input from Mappers to Reducers at every iteration, which explains the significant savings.
Figure 2 shows an overall performance by iteration of HaLoop vs. Hadoop on the Billion Triple data-set. The figure shows that HaLoop scales better than Hadoop since it can cache intermediate results from iteration to iteration.
References
http://code.google.com/p/haloop/
http://homes.cs.washington.edu/~billhowe/pubs/HaLoop.pdf
http://clue.cs.washington.edu/node/14
http://www.slideshare.net/billhoweuw/haloop-efficient-iterative-processing-on-largescale-clusters
rio.ecs.umass.edu/~lgao/ece697_11/15_Haloop_Dhruv.pptx
