Twister
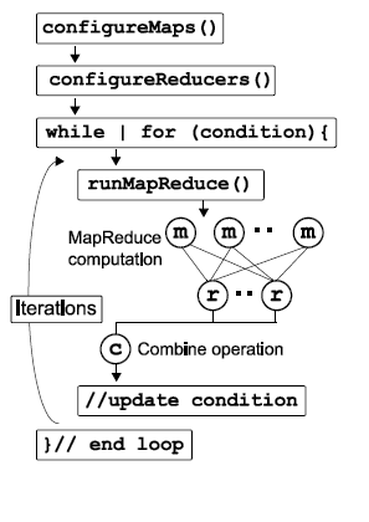
As we discussed that map reduce is really a robust framework manage large amount of data. The map reduce framework has to involve a lot of overhead when dealing with iterative map reduce.Twister is a great framework to perform iterative map reduce.
Additional functionality:
1.) Static and variable Data : Any iterative algorithm requires a static and variable data. Variable data are computed with static data (Usually the larger part of both) to generate another set of variable data. The process is repeated till a given condition and constrain is met. In a normal map-reduce function using Hadoop or DryadLINQ the static data are loaded uselessly every time the computation has to be performed. This is an extra overhead for the computation. Even though they remain fixed throughout the computation they have to be loaded again and again.
Twister introduces a “config” phase for both map and reduces to load any static data that is required. Loading static data for once is also helpful in running a long running Map/Reduce task
2.) Fat Map task : To save the access a lot of data the map is provided with an option of configurable map task, the map task can access large block of data or files. This makes it easy to add heavy computational weight on the map side.
3.) Combine operation: Unlike GFS where the output of reducer are stored in separate files, Twister comes with a new phase along with map reduce called combine that’s collectively adds up the output coming from all the reducer.
4.) Programming extensions: Some of the additional functions to support iterative functionality of Twister are:
i) mapReduceBCast(Value value) for sending a single to all map tasks. For example, the “Value” can be a set of parameters, a resource (file or executable) name, or even a block of data
ii) configureMaps(Value[]values) and configureReduce(Value[]values) to configure map and reduce with additional static data
Twister architecture
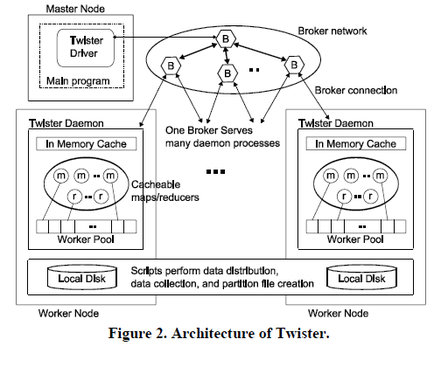
The Twister is designed to effectively support iterative MapReduce function. To reach this flexibility it reads data from the local disk of the worker nodes and handle the intermediate data data in the distributed memory of the workers mode.
The messaging infrastructure in twister is called broker network and it is responsible to perform data transfer using publish/subscribe messaging.
Twister has three main entity:
1. Client Side Driver responsible to drive entire MapReduce computation
2. Twister Daemon running on every working node.
3. The broker Network.
Access Data
1. To access input data for map task it either reads dta from the local disk of the worker nodes.
2. receive data directly via the broker network.
They keep all data read as file and having data as native file allows Twister to pass data directly to any executable. Additionally they allow tool to perform typical file operations like
(i) create directories, (ii) delete directories, (iii) distribute input files across worker nodes, (iv) copy a set of resources/input files to all worker nodes, (v) collect output files from the worker nodes to a given location, and (vi) create partition-file for a given set of data that is distributed across the worker nodes.
Intermediate Data
The intermediate data are stored in the distributed memory of the worker node. Keeping the map output in distributed memory enhances the speed of the computation by sending the output of the map from these memory to reduces.
Messaging
The use of publish/subscribe messaging infrastructure improves the efficiency of Twister runtime. It use scalable NaradaBrokering messaging infrastructure to connect difference Broker network and reduce load on any one of them.
Fault Tolerance
There are three assumption for for providing fault tolerance for iterative mapreduce:
(i) failure of master node is rare adn no support is provided for that.
(ii) Independent of twister runtime the communication network can be made fault tolerant.
(iii) the data is replicated among the nodes of the computation infrastructure. Based on these assumptions we try to handle failures of map/reduce tasks, daemons, and worker nodes failures.
The messaging infrastructure in twister is called broker network and it is responsible to perform data transfer using publish/subscribe messaging.
Twister has three main entity:
1. Client Side Driver responsible to drive entire MapReduce computation
2. Twister Daemon running on every working node.
3. The broker Network.
Access Data
1. To access input data for map task it either reads dta from the local disk of the worker nodes.
2. receive data directly via the broker network.
They keep all data read as file and having data as native file allows Twister to pass data directly to any executable. Additionally they allow tool to perform typical file operations like
(i) create directories, (ii) delete directories, (iii) distribute input files across worker nodes, (iv) copy a set of resources/input files to all worker nodes, (v) collect output files from the worker nodes to a given location, and (vi) create partition-file for a given set of data that is distributed across the worker nodes.
Intermediate Data
The intermediate data are stored in the distributed memory of the worker node. Keeping the map output in distributed memory enhances the speed of the computation by sending the output of the map from these memory to reduces.
Messaging
The use of publish/subscribe messaging infrastructure improves the efficiency of Twister runtime. It use scalable NaradaBrokering messaging infrastructure to connect difference Broker network and reduce load on any one of them.
Fault Tolerance
There are three assumption for for providing fault tolerance for iterative mapreduce:
(i) failure of master node is rare adn no support is provided for that.
(ii) Independent of twister runtime the communication network can be made fault tolerant.
(iii) the data is replicated among the nodes of the computation infrastructure. Based on these assumptions we try to handle failures of map/reduce tasks, daemons, and worker nodes failures.
Performance Evaluation
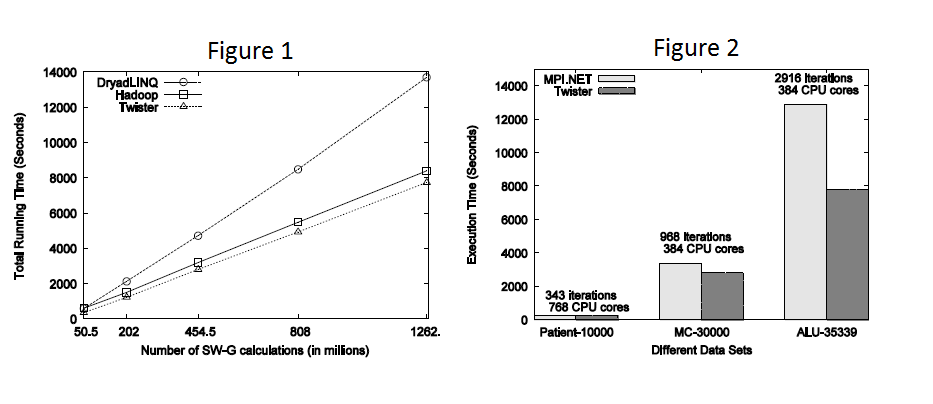
Figure 1 above give the comparison of DryadLINQ, Hadoop and Twister while running an iterative algorithm of SW-G(SW-G is Smith Waterman Gotoh which calculates the distance between each pair of genes in a given gene collection) calculation. We can clearly see that the running time of twister. For performance analysis we use 768 CPU core cluster with 32 nodes.
Figure 2 results indicate that except for the smallest data set which ran for 343 iterations, for the other two cases Twisterperforms better than the MPI implementation. Although the test were performed on the same hardware using the same number of CPU cores, different software stacks were used to perform them. The MPI implementation was run on Windows Server 2008 operating system with MPI.NET while the Twister implementation was run on Red Hat Enterprise 5.4 operating system with JDK 1.6.0.18. A simple comparison on Java and C#performance for matrix multiplication revealed that for the hardware we used, Windows/C# version is 14% slower than the Linux/Java version.
References
http://www.iterativemapreduce.org/
http://grids.ucs.indiana.edu/ptliupages/publications/twister__hpdc_mapreduce.pdf
http://nosql.mypopescu.com/post/21377896197/twister-iterative-mapreduce
http://salsahpc.indiana.edu/content/programming-iterative-mapreduce-applications-using-twister
